
Application of automatic interpretation technology of tunnel rock mass integrity based on digital drilling and multi-scale model fusion
-
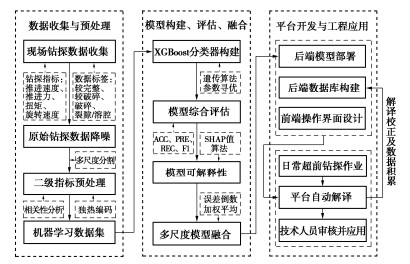
摘要: 在多岩性与多指标钻探数据收集的基础上,综合考虑解译精度与预报效果,借助机器学习工具,提出一种基于数字钻探与多尺度模型融合的隧道岩体完整性自动解译技术。首先,对原始钻探数据有针对性的进行降噪与等距分割(0.5,1,2 m)等预处理,形成多尺度、高质量机器学习数据集;然后,进行模型参数自动寻优、训练、评估与可解释性等操作,验证模型的准确性与可靠性;最后,采用加权平均的方法进行多尺度模型解译结果的融合,以增强该技术的工程实用效果。为方便实际工程应用,以上述技术为核心开发轻量化数字钻探智能解译平台,经多条灰岩与砂岩隧道应用结果表明:对比地质雷达与常规钻探解译,多尺度模型融合解译在解译效率、预测效果等方面总体表现优异,可为隧道施工的开挖与支护提供可靠的岩体完整性信息。Abstract: By collecting the multi-lithology and multi-index drilling data, an automatic interpretation technology of tunnel rock mass integrity based on integrated algorithm and multi-scale model fusion is proposed considering comprehensive interpretation accuracy and practical effect. First, the pre-processing such as noise reduction and equidistant segmentations (0.5, 1 and 2 m) is carried out of the raw data to form a multi-scale, high-quality machine learning dataset. Then the operations such as automatic parameter optimization, training, evaluation and interpretability of model are performed to verify the accuracy and reliability. Finally, the weighted average method is used to fuse the multi-scale interpretation results to enhance the engineering practical effect. In addition, in order to facilitate practical engineering applications, a lightweight automatic interpretation platform is developed. The application results of several limestone and sandstone tunnels show that compared with the conventional interpretation, the multi-scale model fusion interpretation has the overall excellent performance in interpretation efficiency and prediction effect. It can provide reliable rock mass integrity information for the excavation and support of tunnel construction.
-
0. 引言
由于岩土体形成过程涉及多形式且复杂的物化作用,导致岩土体参数存在空间变异性,该变异性对岩土结构物(如:边坡、桩基础、隧道等)具有较大影响,这一事实已逐渐被人们所认识[1-6]。如何准确地表征岩土体参数空间变异性,并进行高效边坡可靠度分析已成为岩土工程领域目前研究热点之一。
岩土体的空间变异性可在随机场理论体系中进行模拟,其中Karhunen-Loève(K-L)级数展开法具有较好的多参数适应性,可以在考虑波动范围的情况下对随机场进行较好的离散[7]。另一方面,为有效地进行边坡可靠度分析,采用代理模型可减少边坡确定性分析模型的调用次数达到降低计算量的目的。代理模型以少量样本点构建近似边坡极限状态函数,进而以代理模型响应值评估边坡失效概率Pf[8]。常用代理模型中的多元自适应回归样条(简称MARS)可以根据输入输出变量之间的关系构建精度较高的模型,无需进行函数形式预设[9-10]。代理模型针对整个样本空间进行选点建模,在不同子空间中精度不同,尤其是在失效域附近样本点较少。为此,部分学者提出在失效域附近进行代理模型的优化,如:苏永华等[11]提出基于Kriging的边坡稳定可靠度主动搜索法;张天龙等[12]提出引入径向基插值函数,结合主动学习的策略,建立数值分析模型的显式代理模型。然而,上述方法均忽略了土体参数的空间变异性,这必将导致评估结果不准确。在考虑边坡土体参数空间变异时,随机场离散的随机变量矩阵往往具有较高的维度,这将导致模型陷入高维诅咒[13]。为解决该问题,部分学者提出对输入的随机变量矩阵进行降维处理。Li[14]提出的充足降维法中的分段逆回归具有较高的可靠性并易于实现而得到广泛的应用。此外,在实际岩土工程中,常会遇见边坡Pf较小的情况,使用传统蒙特卡洛模拟(简称MCS)方法选取计算样本,会出现计算机内存溢出情况,限制了代理模型的应用。
为在考虑参数空间变异性情况下准确高效地开展小失效概率的边坡可靠度分析,本文提出了一种基于分段逆回归的主动学习多元自适应回归样条法与子集模拟结合的边坡可靠度分析方法。首先,介绍了采用K-L展开法模拟土体参数空间变异性的理论。接着,通过分段逆回归方法(简称SIR)降维,将降维后的随机变量矩阵与安全系数(FS)矩阵相结合构建初始MARS模型。其次,利用主动学习函数反复选取最优样本点更新MARS模型,当模型达到阈值要求时,采用子集模拟方法(简称SS)对边坡进行可靠度分析。最后,采用两个典型边坡算例,验证本文所提方法的准确性与稳健性。
1. 岩土体参数空间变异性表征
1.1 岩土体参数的空间变异性
岩土体内各点之间存在一定的相关性,土体内任意两点之间的关系通常采用自相关函数表示。高斯型自相关函数具有连续可导的优点[14],本文选取该自相关函数,具体的表达式为
ρ(ψx,ψy)=1/exp[ν2xλ2h+ν2yλ2v]。 (1) 式中:ρ(ψx, ψy)为自相关函数;λh和λv分别为水平与垂直相关距离;νx和νy分别为岩土体内两点对应坐标的差值。
1.2 基于Karhunen-Loève展开法的空间变异岩土体特征参数模拟
在保证精度的前提下,通常截取前r个较大的特征值和相对应的特征向量,以提高计算效率。将对数随机场H离散为一组独立标准随机变量,对于第i(i=1, 2, 3, …, N)个随机场K-L离散结果可表示为[7]
˜Hi(x,y)=exp(μlni+r∑j=1σlni√λifj(x,y)χi,j)( i=c,φ)。 (2) 式中:i为需要离散的参数;λj和fj(x,y)分别是自相关函数中第j个特征值和特征函数;c和φ分别为土体的黏聚力与内摩擦角;χi,j为相关标准正态随机变量,由独立标准正态随机样本矩阵转化得到;μlni和σlni分别为对应标准正态分布参数lni的均值与标准差,μlni=lnμi−0.5σ2lni,σlni=√ln(1+(σi/μi)2)。μi和σi分别为土体参数的平均值和标准差。
2. 基于分段逆回归的主动学习多元自适应回归样条法介绍
本节选择SIR法用于降维,再结合代理模型,构建能解决高维问题且计算效率高的代理模型。
2.1 分段逆回归降维方法
SIR方法的降维思想是以输入变量及因变量的相关关系,将原始空间划为整合,在高维变量中构造少量的线性组合,基于这些线性组合得到新的变量表示原高维空间信息[14]。
首先计算训练样本均值ˉξl的协方差矩阵ˆC。求解矩阵ˆC的特征值及对应的特征向量,据此找到主方向。根据SIR主方向,将输入变量x线性组合得到新变量。每一个方向向量对应一个变量。前k个方向向量为[ˆβ1,ˆβ22,⋯,ˆβk],可得
ωQ=ˆβ′1x=ˆβ′11x1+ˆβ′12x2+,⋯,+ˆβ′1rxr (Q=1,2,⋯,k), (3) 式中,ωQ=ˆβ′1x为第Q个SIR变量。求解并且找到最大的特征值是SIR降维是否有效的关键所在[15]。
2.2 多元自适应回归样条法
多元自适应回归样条法是一种基于分段策略的非线性、非参数回归方法[13]。在系统中,实函数f(ξ)可以表示为
f(ξ)≈ˆf(ξ)=a0+M∑m=1amBm(ξ)。 (4) 式中:ˆf(ξ)为MARS模型输出的预测值;ξ= (ξ1,ξ2,⋯,ξt)为一组输入变量;am为第m个基函数的系数,系数am通过训练样本的最小二乘拟合获得。
MARS算法分为前向选择和后向剪枝两个过程。前向过程算法只从一个常数项基B0(x)=1开始,每次迭代产生两个新的基函数,然后对新的基函数进行标识,最后得到近似模型。每次迭代更新的模型如下:
ˆf(ξ)=a0+M∑m=1amBm(ξ)+ˆam+1Bi(ξ).max(0,xj−t)+ˆam+2Bi(ξ)max(0,t−xj)。 (5) 式中:ˆam+1与ˆam+2可以对输入样本进行最小二乘拟合计算;Bi(ξ)为先前确定的基函数,0⩽。
一般来说,前向过程算法会产生过拟合模型,因为MARS算法允许使用前一个基函数构造新的基函数,导致初始基函数的贡献减小。因此,应采用后向过程算法来提高模型的预测能力。后向过程算法采取的是每次循环,将原有的基函数删除,得到子模型,使用的是泛化交叉实验准则(GCV),GCV最小时模型最优[17],具体形式表示如下:
{\rm GCV} = {{\frac{1}{N}\sum\limits_{i = 1}^N {{{\left[ {{y_i} - {{\hat f}_M}({x_i})} \right]}^2}} } \mathord{\left/ {\vphantom {{\frac{1}{N}\sum\limits_{i = 1}^N {{{\left[ {{y_i} - {{\hat f}_M}({x_i})} \right]}^2}} } {{{\left[ {1 - \frac{{C(M)}}{N}} \right]}^2}}}} \right. } {{{\left[ {1 - \frac{{C(M)}}{N}} \right]}^2}}} 。 (6) 式中:d为惩罚因子,一般取3;C(M)为该模型有效系数的个数;{\hat f_M}({x_i})为在样本点{x_i}对应的预测值。
2.3 主动学习函数
主动学习函数选取的样本点是模型收敛快慢的影响因素之一。当样本点选取在失效临界面附近,可以获得需要的有效信息加快模型收敛,并且每次选取的最优样本点之间有一定的距离防止重复取点。Li等[16]提出了一种考虑样本点相关距离主动学习函数:
{\boldsymbol{u}}_{\rm{a}} = \underset{\boldsymbol u}{\arg \min } \frac{{(1 + \left\| {\boldsymbol{u}} \right\|)|\hat G({\boldsymbol{u}};{T_{N - 1}})|}}{{\frac{{d({\boldsymbol{u}},{T_{N - 1}})}}{{1 + \exp \{ - 20[d({\boldsymbol{u}},{T_{N - 1}}) - {d_{\min }}({T_{N - 1}})]\} }}}} 。 (7) 式中: d({\boldsymbol{u}},{T_{N - 1}}) 为样本池集中点与独立标准正态空间中样本点之间的最小距离; \hat G({\boldsymbol{u}};{T_{N - 1}}) 为代理模型的预测值; {d_{\min }}({T_{N - 1}}) 为最优样本点间最小距离[17]。
2.4 模型终止条件
收敛条件对于构造代理模型尤为重要,因为及时停止最优样本点的增加可以减少计算迭代次数,提高模型构建的效率。通常在失效域与安全域的交界处取得足够的采样点,并且要保证迭代次数与得到的模型精度达到最优。而且计算迭代终止后,模型的参数指标波动范围较小。本文截取计算迭代过程最后5次计算的失效概率P_{\rm{f}}^{{\rm{LAT}}(5)}。当P_{\rm{f}}^{{\rm{LAT}}(5)}的变异系数小于或等于某个阈值{\varepsilon _{\rm{end}}},本次设计阈值选取{\varepsilon _{\rm{end}}} = 0.0001作为迭代终止条件,最后5次计算值的变异系数{{\rm{COV}}_{P_{\rm{f}}^{{\rm{LAT}}(5)}}}可表示为
{{\rm{COV}}_{P_{\rm{f}}^{{\rm{LAT}}(5)}}} = \frac{{{\sigma _{P_{\rm{f}}^{{\rm{LAT}}(5)}}}}}{{\mu {}_{P_{\rm{f}}^{{\rm{LAT}}(5)}}}} \leqslant {\varepsilon _{\rm{end}}}。 (8) 式中:{\sigma _{P_{\rm{f}}^{{\rm{LAT}}(5)}}}为最后5次计算值的方差;\mu {}_{P_{\rm{f}}^{{\rm{LAT}}(5)}}为最后5次计算值的均值。
2.5 子集模拟
当最优样本点选取程序终止,SIR-AMARS模型可直接根据样本点集合预测FS。SS方法是将概率空间划分成一系列子集,子集的生成是通过中间失效事件,将小失效概率分解为若干个较大条件概率的乘积,且这些较大的条件概率较易获得。具体形式如下:
{P_{\rm{f}}} = P({F_{\rm{S}}}(x) - 1 < 0) = P({F_1})\prod\limits_{l = 2}^s {P({F_l}|{F_{l - 1}})} 。 (9) 式中:s为子集模拟层数;P( \cdot )为某事件的概率;{F_l} = \{ {F_{\rm{S}}}({\boldsymbol{x}}) - 1 < {g_l}(x),l = 1,2,3, \cdots ,s\} ;P({F_1})可使用MCS直接进行计算,可表示为
P({F_1}) = \frac{1}{{{N_{\rm{all}}}}}\sum\limits_{t = 1}^{{N_1}} {{I_{{F_1}}}} (x_t^{(1)}){\text{ }}(k = 1,2,3, \cdots ,{N_{\rm{all}}}) 。 (10) 式中: x_t^{(1)} 为独立同分布样本点,由概率密度分布函数计算得到; {I_{{F_1}}}( \cdot ) 为指示函数。
3. SIR-AMARS-SS方法执行步骤
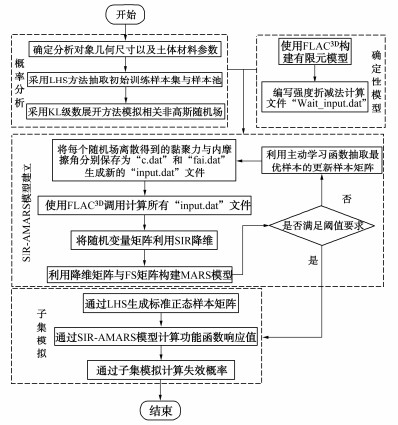
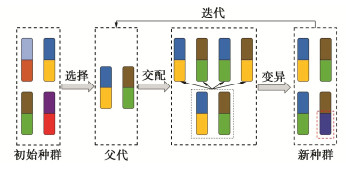
本节给出了基于SIR-AMARS-SS的边坡可靠度分析方法的具体过程,图 1为相应的计算流程图,具体步骤如下:
![]() 图 1 SIR-AMARS-SS边坡可靠度计算流程图Figure 1. Flow chart for calculation of slope reliability by SIR-AMARS-SS
图 1 SIR-AMARS-SS边坡可靠度计算流程图Figure 1. Flow chart for calculation of slope reliability by SIR-AMARS-SS(1)确定分析对象的几何尺寸,以及土体材料特征参数及其统计特征(如黏聚力c、内摩擦角φ、密度,以及其均值、方差、波动范围等)
(2)借助FLAC3D软件,根据几何参数构建边坡模型,并且编写MATLAB程序提取各个单元形心点坐标({x_{\boldsymbol{t}}},{y_{\boldsymbol{t}}}),其中t=1,2,3, …,m, m为单元数。使用Fish语言编写待输入各个单元参数值的强度折减法(SRM)程序,保存程序文件名为“input.dat”。
(3)使用拉丁超立方抽样(LHS)抽取大小为(M \times {N_{\rm m}}) \times {N_{\rm S}}的初始样本矩阵 \xi 与大小为(M \times {N_{\rm F}}) \times {N_{\rm T}}初始样本池矩阵T。M为K-L展开法截断后留下的项数,{N_{\rm m}}为边坡有限元模型单元个数,{N_{\rm S}}为建立初始代理模型需要的样本点个数,{N_{\rm T}}为样本池中样本点个数。随后将矩阵 \xi 标准化,得到矩阵Γ。
(4)根据已知信息,使用K-L展开法生成随机场,并保证离散后的随机场大小与有限元模型单元数{N_{\rm m}}一致。将每一个随机场模型的单元c、φ值保存为文件“c.dat”和“f.dat”,并生成{N_{\rm S}}个新的“input.dat”文件。
(5)使用FLAC3D软件调用“input.dat”文件,将文件“c.dat”和“f.dat”中的参数赋值于各个单元。随后进行SRM计算,得到{N_{\rm S}}个FS。
(6)利用SIR对独立标准正态的随机样本矩阵 \xi 进行降维操作,采用2.1节所给出的步骤得到k维的随机样本矩阵η。
(7)根据随机样本矩阵η和矩阵FS,采用2.2节所介绍的方法构建最初的MARS模型,并根据2.4节所给出的阈值验证模型的精确性。
(8)如果模型不满足阈值所需要的精确度要求,则采用2.3节介绍的方法调用主动学习函数,选取样本池中最优点xt,加入到初始训练样本集内,再次更新MARS模型。
(9)当模型达到迭代停止的阈值要求,将最终得到的SIR-AMARS模型与SS结合,计算Pf。
4. 算例一:单层c-φ边坡
本节的研究对象为单层c-φ边坡,考虑岩土体抗剪强度参数空间变异性进行边坡可靠度分析。此外,验证不同互相关系数情况下模型的鲁棒性。
4.1 算例一边坡的描述与确定性分析
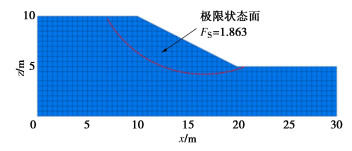
图 2给出了所研究的边坡几何形状,坡高5 m,边坡水平长度为10 m。土体弹性模量E=100 MPa,土体重度 \gamma =20 kN/m3,泊松比 \nu =0.3。假定c与φ均服从对数正态分布。稳定性分析所需的土体参数统计特征见表 1。本次边坡可靠度分析仅考虑土体c和φ参数的空间变异性,边坡FS计算基于弹塑性模型以及莫尔库仑破坏准则,其余土体参数均以常数赋值。根据表 1土体参数均值建立初步模型,借助FLAC3D建模,并利用SRM计算得到FS为1.863,图 2给出了破坏时的滑动面位置以及形状。与Jiang等[18]得到的1.78相近,安全系数相对误差为4.66%,表明所建立的边坡确定性模型的正确性。
表 1 算例一岩土体参数统计特征Table 1. Statistical characteristics of geotechnical parameters for Example Ⅰ土体参数 均值 变异系数 分布情况 互相关系数 c 10 kPa 0.3 对数分布 0 φ 20° 0.2 对数分布 图 2给出了建立模型时网格划分情况,本次建模包含910个单元。为与先前学者研究结果对比,网格划分情况与Jiang等[19]模型划分情况保持一致。并且假设波动范围分别为δh=25 m,δv=2.5 m,采用K-L展开方法对边坡c-φ随机场进行离散,此过程将参数赋予每个单元质心,以质心参数代表整个单元的土体参数值。基于以上所述条件进行边坡可靠度分析。
4.2 算例一边坡可靠度结果分析
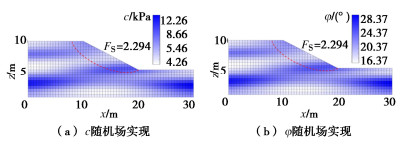
根据表 1中土体参数,采用K-L展开法进行随机场的实现,为保证随机场离散化精度,随机场中土体参数c与φ的截断展开项数均为21,从而得到42个随机变量。图 3给出了所研究的边坡抗剪强度参数随机场一次典型实现及稳定性分析结果。
一般情况下,面对维度较高的问题,代理模型会陷入高维诅咒。因此,在构建代理模型之前,将随机变量矩阵进行降维处理。而降维会舍去一部分信息量,模型精度可能会受到一定量的损伤。为找到降维效果最为显著(即降维数最小,且不会对可靠度分析结果几乎不会造成影响)的维数k,并得到初始样本数最少且精度较高的平衡点,需要有一个指标评价模型在不同情况下的准确性。本文中采用均方根误差RMSE评估SIR-AMARS代理模型的精确度,计算公式如下:
{\rm {RMSE}} = \sqrt {\frac{{\sum\limits_{s = 1}^{{N_s}} {{{({{\rm FSS}_s} - {{\rm FSP}_s})}^2}} }}{{{N_s}}}} 。 (11) 式中:{{\rm FSS}_s}为利用SIR-AMARS代理模型预测得到的安全系数;{{\rm FSP}_s}为通过SRM计算得到的安全系数;Ns为用于计算均方根误差的样本数目。
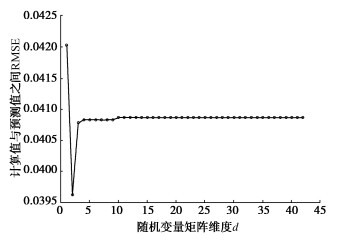
为确定模型降维效果最为显著的维数,设置初始训练样本数1000个,使用SIR将随机变量矩阵降维后,与使用SRM计算所的FS构建MARS模型。另取1000个样本,改变模型设置中降维后的维数k,计算预测值与无偏估计值之间在不同维度下的RMSE,结果如图 4所示。由于当k=4时,RMSE的值为0.0408,此时的代理模型已经非常准确,因此本次研究将维度降为4。
![]() 图 4 均方根误差与降维变化对比图Figure 4. Comparison diagram of root mean square error and dimensionality reduction
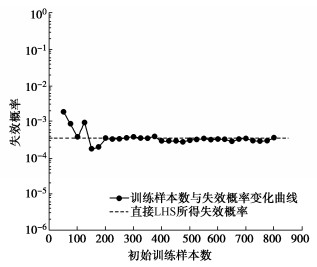
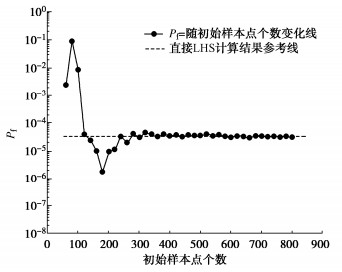
图 4 均方根误差与降维变化对比图Figure 4. Comparison diagram of root mean square error and dimensionality reduction模型预测能力的优劣,关键因素之一是用于构建代理模型的训练样本点数,用于构建代理模型的初始样本点数量与模型预测结果精度呈正比。但是用于构建模型的训练样本需要经过SRM进行计算,而训练模型的初始样本点数与构建模型所需要的时间呈正比,所以需要找到在不影响模型精度的前提下初始训练样本最少的数量。为寻求构建模型样本数的最优值,采用LHS抽取生成1000个独立标准正态分布样本矩阵 \xi ,通过随机场离散获得对应边坡随机场实现,进而利用SRM计算FS。设置初始训练样本数从50开始,随着训练样本的增加边坡Pf的变化如图 5所示。从图 5中可以看出,当初始训练样本达到200时,Pf值基本稳定。所以,在本节中,选取200个初始训练样本用于构建代理模型。
![]() 图 5 初始训练样本数与失效概率变化对比图Figure 5. Comparison diagram of number of initial training samples and change of failure probability
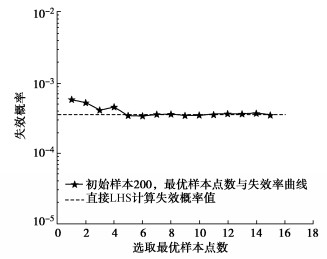
图 5 初始训练样本数与失效概率变化对比图Figure 5. Comparison diagram of number of initial training samples and change of failure probability当初始训练样本确定为200个,最优样本点的选取个数为9时模型构建已完成,为证明此时的模型已经达到收敛状态,继续抽取6个最优样本点。图 6给出了随着最优样本点个数增加,Pf的变化情况。由图 6可知,当抽取最优样本点数为9时,所得到的结果已经满足主动学习函数的阈值,停止选取样本点,并且计算结果已经趋于稳定。
![]() 图 6 最优样本点增加与失效概率变化对比图Figure 6. Comparison diagram of increase of optimal sample points and change of failure probability
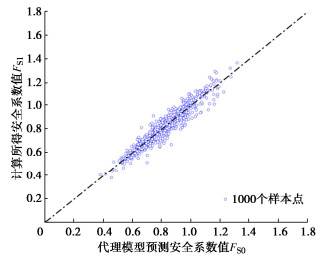
图 6 最优样本点增加与失效概率变化对比图Figure 6. Comparison diagram of increase of optimal sample points and change of failure probability使用LHS任意抽取1000组样本,并得到其对应的边坡随机场实现,利用FLAC3D软件计算得到安全系数的无偏估计值矩阵FS0,再将训练样本使用上述得到的SIR-AMARS模型进行预测,得到预测安全系数矩阵FS1,将无偏估计值矩阵FS0与预测安全系数矩阵FS1进行对比,结果可见图 7。不难发现,当维度最终降为4,且初始训练样本数为200,利用主动学习函数抽取最优样本点9个时(即最终使用209个训练样本构建SIR-AMARS模型),已经能得到精准度较高的SIR-AMARS模型。随后,将最终得到的SIR-AMARS模型与SS结合,设置计算样本数为3000,最终得到此边坡Pf为3.556×10-4。
![]() 图 7 计算所得安全系数与代理模型预测安全系数值对比图Figure 7. Comparison between calculated safety factor and predicted safety factor by surrogate model
图 7 计算所得安全系数与代理模型预测安全系数值对比图Figure 7. Comparison between calculated safety factor and predicted safety factor by surrogate model为证明本文所提方法的准确性以及计算的高效性,将本文所述方法与二阶Hermite混沌展开多项式(二阶PCE)(训练样本数462个和2500个,两种情况)、三阶Hermite混沌展开多项式(三阶PCE)、直接拉丁超立方模拟对此边坡计算Pf结果进行对比。为比较不同分析方法之间的差异,本文使用直接LHS抽取1×105个样本,使用FLAC3D直接计算得到了Pf无偏估计值,再将各种分析方法算得的Pf与其对比,采用了相对误差∆用于比较各种方法的准确度。相对误差的计算公式如下:
\varDelta=\left|\frac{\mathrm{PF}_{\mathrm{c}}-\mathrm{PF}_{\mathrm{p}}}{\mathrm{PF}_{\mathrm{p}}}\right| \times 100 \% 。 (12) 式中:\varDelta 为相对误差值;\mathrm{PF}_{\mathrm{c}}为代理模型计算得到的失效概率;\mathrm{PF}_{\mathrm{p}}为直接LHS方法算得的失效概率。计算结果见表 2。
表 2 不同分析方法对算例一计算失效概率结果Table 2. Failure probability results calculated by different analysis methods for Example Ⅰ由表 2可知,本文所提方法在训练代理模型时,所需要的训练样本数最少,仅需要209个。并且,本文所提方法与使用直接LHS计算得到的Pf之间的相对误差仅为1.22%,优于其他方法。并且所使用的训练样本数及计算样本数最少,说明了本文所提方法具有高效计算能力以及精准度。需要特别说明的是,如果需要更高的计算精度,例如计算样本数大于108时,计算样本的模拟内存将超过设备物理内存(计算机内存条16 GB),导致内存溢出情况,因此在概率更小的问题时,使用MCS模拟法存在局限性[18]。但基于SIR-AMARS模型的SS方法,在与MCS法计算结果相近的情况下,仅需要3×103个计算样本,很好地解决了其他代理模型计算小失效概率事件导致内存溢出无法计算的问题。为增加处理问题高效性,以下研究均基于SIR-AMARS-SS模型。
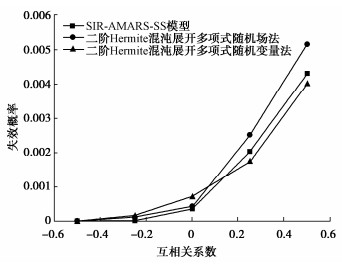
为研究抗剪强度参数之间的相关程度对边坡可靠度分析的影响,本文选取-0.5 ≤ρcφ ≤ 0.5,假定 {\lambda _{\rm{h}}} =25 m, {\lambda _{\rm{v}}} =2.5 m,对比了二阶Hermite混沌展开多项式随机变量法、二阶Hermite混沌展开多项式随机场法与基于SIR-AMARS-SS模型随机场法计算结果。图 8比较了3种方法随着的ρcφ变化Pf的结果,由图 8可知,在互相关系数ρcφ从-0.5逐渐变为0.5,Pf变化几个数量级(Pf从3.9×10-6变至4.32×10-3),说明抗剪强度参数之间的互相关系数对边坡失效概率影响较大。并且二阶Hermite混沌展开多项式随机变量法在c与φ处于较大正相关系数时,低估了边坡的Pf,所得结果与Jiang等[18]得到的结论一致,同时也证明本文所提方法在面对土体强度参数相关性不同的情况下,依然有较好的预测能力。由此表明,本文所提方法,训练样本数以及计算样本数需求量最低,节省计算量明显,并且能适用于土体抗剪强度不同的相关性情况。
![]() 图 8 不同分析方法随ρcφ变化失效概率对比图Figure 8. Comparison diagram of failure probability by different analysis methods with change of ρcφ
图 8 不同分析方法随ρcφ变化失效概率对比图Figure 8. Comparison diagram of failure probability by different analysis methods with change of ρcφ4.3 降维对安全系数的影响分析
在本节算例中,采用了SIR降维,随机变量矩阵维度从42降至4,在此过程中,必然会有一部分信息丢失,为确定降维是否会对边坡可靠度分析造成较大的影响,必须讨论降维前后FS变化情况。
基于上述模型,使用拉丁超立方随机抽取500个初始样本生成随机场,首先使用SRM直接计算得到安全系数FSN,使用已经构建的SIR-AMARS模型进行预测,得到预测安全系数FSS。在本节中,采用决定系数R2表示降维对FS的影响,其中R2∈(0, 1)。R2越接近1,表示SIR降维对失效概率影响越低。其中R2的计算公式为
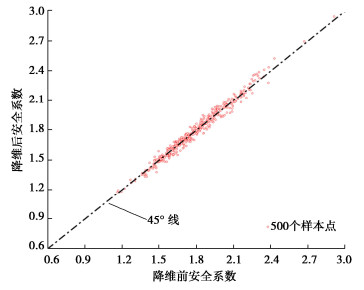
R^2=1-\frac{\sum\limits_{i=1}^N\left(\mathrm{FS}_S-\mathrm{FS}_N\right)^2}{\sum\limits_{i=1}^N\left(\mathrm{FS}_N-\overline{\mathrm{FS}}\right)^2} (13) 式中,N是样本数目;FSS是使用SIR-AMARS模型预测得到的安全系数;FSN使用SRM直接计算得到安全系数;FS是FSN的均值。最终算得的决定系数R2=0.9773,并且将安全系数矩阵FSN与预测安全系数矩阵FSS依次对应画图,最终结果可见图 9,由决定系数值及图 9可知,降维对FS的计算结果没有造成大的影响。
![]() 图 9 降维前后安全系数对比图Figure 9. Comparison diagram of safety factor before and after dimension reduction
图 9 降维前后安全系数对比图Figure 9. Comparison diagram of safety factor before and after dimension reduction为进一步讨论降维对边坡可靠度分析的影响,随机选择两组随机变量矩阵,模拟降维前后c与φ的随机场。具体的模拟情况可见图 10,随机场Ⅱ与Ⅳ分别是随机场Ⅰ与Ⅲ降维后的情况,随机场内的空间变异性程度有所降低,但降维并没有导致FS有较大的变化。造成空间变异性程度降低主要是因为在降维时,SIR会丢弃一部分不重要的信息。在边坡安全系数的计算中,影响其数值大小最关键的一部分就是滑动面底部的参数情况[19]。
![]() 图 10 降维前后随机场对比图Figure 10. Comparison of random field before and after dimension reduction
图 10 降维前后随机场对比图Figure 10. Comparison of random field before and after dimension reduction5. 算例二:双层非均质边坡
本节的研究对象为双层边坡,仅考虑c的空间变异性,进行边坡可靠度分析。
5.1 算例二边坡的描述于确定性分析
本节研究对象为双层非均质边坡,边坡高度为24 m,坡角为36.87°(3h∶4v)。c的变异系数均为0.4,上下层c的分布类型均为高斯型,土体重度为19 kN/m3。建模所需要的土体抗剪强度参数见表 3,将边坡划分为1296个单元。
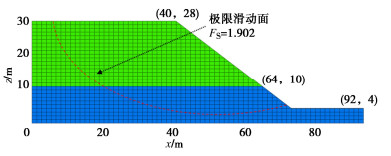
表 3 算例二岩土体抗剪强度参数统计表Table 3. Statistical table of shear strength parameters of slope soil for Example Ⅱ参数 均值 自相关距离 分布类型 黏聚力c 上层,120 kPa λh = 20 m 对数正态分布 下层,160 kPa λv = 2 m 本文采用FLAC3D计算FS,得到边坡安全系数为1.902。具体的破坏滑面可见图 11所示,滑动面穿过两层土体,并且滑动面沿着底部边界,破坏形式和FS与文献[20,21]的滑动面形状与FS值2.02和1.993基本保持一致,验证了本节建模的准确性。
5.2 算例二边坡可靠度结果分析
为将参数空间变异性考虑进边坡可靠度分析,本节依旧使用K-L展开法进行随机场模拟,本节算例仅考虑了c的空间变异性,为满足离散化精度,需要产生65个随机变量,其中上层随机变量为36个,下层随机变量为29个。图 12展现了一次典型随机场实现形式。
为确定本文所提方法针对本节算例所需要的最少样本数,首先利用LHS抽取生成3×104个独立的标准正态分布样本矩阵 \zeta 。进而获得边坡随机场实现,通过SRM计算FS,直接计算得到失效概率。将样本矩阵从前往后,从60个初始训练样本开始,依次增加训练样本数,直至训练样本数到800个结束,每次都使用训练样本构建新的SIR-AMARS模型。构建模型时,SIR降维后随机变量矩阵的维数k=10,将每次得到的模型与SS结合计算失效概率(其中SS的计算样本数定为3000),构建训练样本数与Pf相关关系如图 13所示。从图 13中可以看出,当初始训练样本为300时,模型已经趋于稳定,可以应用于本节双层边坡可靠度分析之中。当初始训练样本确定为300个时,最优样本点的选取个数为13时(即用于构建代理模型的训练样本数为313个),模型已经完成构建,此时随机场的随机变量矩阵维数k=10。将样本矩阵 \zeta 的前300个样本作为训练样本,构建SIR-AMARS模型,最后将此模型结合SS,抽取的样本数为3000,计算失效概率。
为进行对比,选取二阶Hermite响应面方法,人工神经网络对本节算例进行可靠度分析,由于本节算例将土体参数离散有65个随机变量,二阶Hermite的待定系数为67!/2!65! = 2211项。二阶Hermite随机多项式4500个样本,神经网络选取500个样本作为对比。最终的计算结果见表 4。从表 4可知,本文所提方法计算得到的Pf与直接LHS计算所得的Pf相最为接近,在保证精度的情况下,使用的训练样本数最少,计算耗时最短(基于电脑配置为I7-10700,16 G运行内存情况)。这进一步验证了所提方法的高效性。
表 4 不同分析方法对算例二计算失效概率结果Table 4. Failure probability results of Example Ⅱ calculated by different analysis methods分析方法 训练样本 失效概率 计算耗时/h 二阶Hermite 4500 4.10×10-5 225 人工神经网络 500 4.91×10-5 25 SIR-AMARS-MCS 313 3.56×10-5 15.65 LHS 3×104 3.33×10-5 1500 6. 结论
为在考虑参数空间变异性情况下准确高效地开展小失效概率的边坡可靠度分析,本文提出了一种基于SIR-AMARS-SS代理模型的分析方法,并验证了所提方法的有效性,得到以下3点结论。
(1)在考虑参数空间变异性情况下进行小失效概率边坡可靠度分析时,所提方法可以较少的训练样本以及计算样本得到较为精准的结果,极大地降低了调用原边坡有限元模型计算次数,并且避免由于抽样个数过多而导致的物理内存溢出情况。
(2)本文所提方法在面对高维度问题,不会陷入高维灾难,且在高维情况下得到快速收敛的结果,所得结果具有较高的计算精度。
(3)在使用SIR降维时,会导致随机变量矩阵丢失一部分信息,造成随机场的空间变异性变低,但是对模型预测FS影响较小。
-
![]()
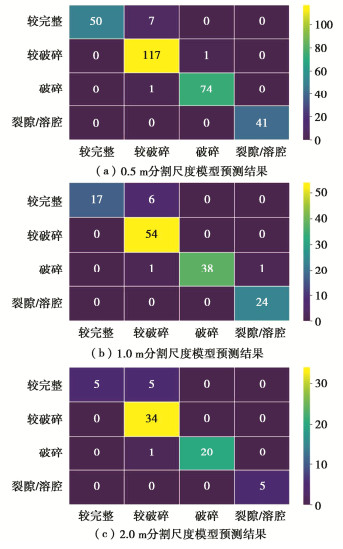
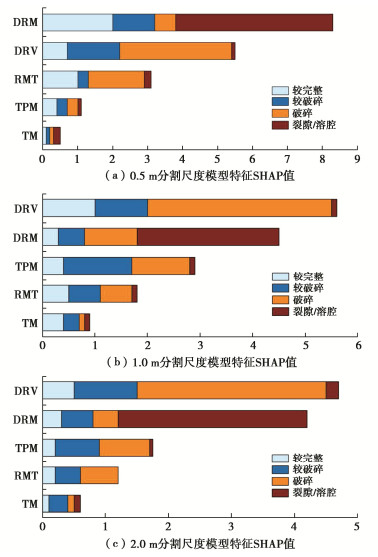
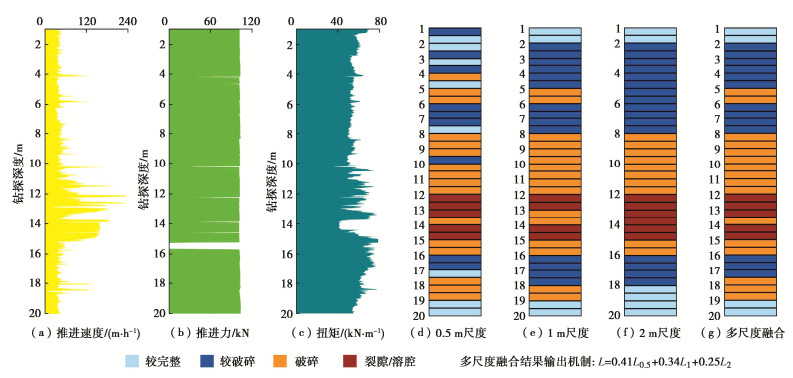
图 10 各尺度模型解译效果及多尺度模型融合解译效果
Figure 10. Interpretation effects of each scale model and multi-scale model fusion
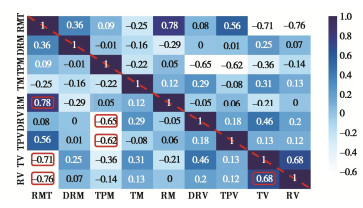
表 1 数据集特征及其数字描述
Table 1 Dataset features and their numerical descriptions
特征 最小值 最大值 中值 均值 RMT — — — — DRM 12.39 207.80 31.44 49.16 TPM 96.35 109.09 102.39 103.03 TM 35.14 86.77 49.51 52.25 RM 64.60 182.01 144.99 139.61 DRV 1.24 2555.04 37.43 178.46 TPV 0.52 398.52 1.35 3.79 TV 0.17 153.11 3.38 10.02 RV 0.84 260.41 13.65 26.57  下载: 导出CSV
下载: 导出CSV
表 2 数据集特征及其数字描述
Table 2 Dataset features and their numerical descriptions
超参数 0.5 m 1.0 m 2.0 m n_estimators 106 83 72 max_dept 7 8 8 learning_rate 0.21 0.30 0.50 min_child_weight 0.45 0.13 0.53 subsample 0.68 0.45 0.37 colsample_bytree 0.95 0.91 0.72
下载: 导出CSV
表 3 数据集特征及其数字描述
Table 3 Dataset features and their numerical descriptions
类别 尺度/m ACC/% PER/% REC/% F1/% GA寻优 0.5 96.91 98.07 96.38 97.11 1.0 94.32 96.13 92.23 93.58 2.0 91.43 96.25 86.31 89.03 未寻优 0.5 92.86 95.00 92.19 92.59 1.0 91.84 92.17 89.52 90.70 2.0 87.55 90.05 84.64 87.26
下载: 导出CSV
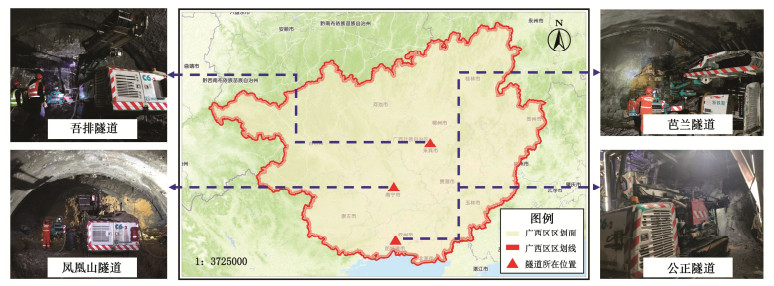
表 4 隧道工程技术应用统计表(部分)
Table 4 Statistics of technological applications in tunnels (part)
隧道及岩性 掌子面及超前钻探预报里程 地质雷达结论 超前钻探解译 实际揭露岩体完整性情况 孔号 常规人工解译 多尺度模型融合自动解译 百宝隧道(砂岩) 
该里程段岩体较破碎,节理裂隙较发育,层理较发育,结合差 1 (1)整体为较破碎 (1)较完整—较破碎,分别占比55.56%与44.44% 总体较完整—较破碎,其中26~27 m发育有薄层状软弱夹层 2 (1)整体为较破碎
(2)26~28 m疑似发育有波层状软弱夹层(1)较完整—较破碎,分别占比77.59%与20.69%
(2)26.5~27 m疑似发育有薄层状软弱夹层龙湾2号隧道(灰岩) 
该里程段围岩岩体破碎,结构面夹泥,溶蚀裂隙发育,发育有泥质填充型溶洞 1 (1)1~11 m疑似发育泥质填充型溶洞
(2)12~24 m较破碎(1)1.5~4 m、5~11 m疑似发育泥质填充型溶洞,4~5 m为破碎岩体
(2)12~24 m总体较完整—较破碎,分别占比20.83%与41.67%1~11 m为较破碎—破碎,11~22 m为较完整—较破碎,其中1.5 m附近发育有薄层溶蚀裂隙,2~10 m密集发育泥质填充溶洞,且溶洞规模较大 2 (1)1~12 m整体破碎,其中5~8 m疑似发育有泥质填充溶洞
(2)13~22 m较完整—较破碎(1)1~12 m整体破碎,其中2~2.5疑似发育有薄层状裂隙/空腔,5~7.5 m疑似发育有泥质填充溶洞
(2)13~22 m总体较完整—较破碎,分别占比43.04%与28.70%
下载: 导出CSV
-
[1] 李术才, 刘斌, 孙怀凤, 等. 隧道施工超前地质预报研究现状及发展趋势[J]. 岩石力学与工程学报, 2014, 33(6): 1090-1113. LI Shucai, LIU Bin, SUN Huaifeng, et al. State of art and trends of advanced geological prediction in tunnel construction[J]. Chinese Journal of Rock Mechanics and Engineering, 2014, 33(6): 1090-1113. (in Chinese)
[2] 晏军. 岩溶隧道超前地质预报几种主要物探方法的选择与实践[J]. 隧道建设(中英文), 2020, 40(增刊1): 327-336. YAN Jun. Selection and application of several main geophysical methods for advanced geological prediction of Karst tunnels[J]. Tunnel Construction, 2020, 40(S1): 327-336. (in Chinese)
[3] 周轮, 李术才, 许振浩, 等. 隧道综合超前地质预报技术及其工程应用[J]. 山东大学学报(工学版), 2017, 47(2): 55-62. ZHOU Lun, LI Shucai, XU Zhenhao, et al. Integrated advanced geological prediction technology of tunnel and its engineering application[J]. Journal of Shandong University (Engineering Science), 2017, 47(2): 55-62. (in Chinese)
[4] 岳中琦. 钻孔过程监测(DPM)对工程岩体质量评价方法的完善与提升[J]. 岩石力学与工程学报, 2014, 33(10): 1977-1996. YUE Zhongqi Drilling process monitoring for refining and upgrading rock mass quality classification methods[J]. Chinese Journal of Rock Mechanics and Engineering, 2014, 33(10): 1977-1996. (in Chinese)
[5] PFISTER P. Recording drilling parameters in ground engineering[J]. Ground Engineering, 1985, 18(3): 16-21.
[6] GUI M, SOGA K, Bolton, et al. Instrumented borehole drilling using ENPASOL system Field Measurements of Geomechanics, 1999.
[7] WANG Q, GAO H K, JIANG B, et al. In-situ test and bolt-grouting design evaluation method of underground engineering based on digital drilling[J]. International Journal of Rock Mechanics and Mining Sciences, 2021, 138: 104575. doi: 10.1016/j.ijrmms.2020.104575
[8] 梁栋才, 汤华, 吴振君, 等. 基于多钻进参数和概率分类方法的地层识别研究[J]. 岩土力学, 2022, 43(4): 1123-1134. LIANG Dongcai, TANG Hua, WU Zhenjun, et al. Stratum identification based on multiple drilling parameters and probability classification[J]. Rock and Soil Mechanics, 2022, 43(4): 1123-1134. (in Chinese)
[9] SCHUNNESSON H, FALKSUND H, GUSTAFSON A, et al. Assessment of rock mass quality using drill monitoring technique for hydraulic ITH drills[J]. International Journal of Mining and Mineral Engineering, 2017, 8(3): 169. doi: 10.1504/IJMME.2017.085830
[10] ELDERT J, SCHUNNESSON H, JOHANSSON D, et al. Application of measurement while drilling technology to predict rock mass quality and rock support for tunnelling[J]. Rock Mechanics and Rock Engineering, 2020, 53(3): 1349-1358. doi: 10.1007/s00603-019-01979-2
[11] WU Z J, WEI R L, CHU Z F, et al. Real-time rock mass condition prediction with TBM tunneling big data using a novel rock-machine mutual feedback perception method[J]. Journal of Rock Mechanics and Geotechnical Engineering, 2021, 13(6): 1311-1325. doi: 10.1016/j.jrmge.2021.07.012
[12] 房昱纬, 吴振君, 盛谦, 等. 基于超前钻探测试的隧道地层智能识别方法[J]. 岩土力学, 2020, 41(7): 2494-2503. FANG Yuwei, WU Zhenjun, SHENG Qian, et al. Intelligent recognition of tunnel stratum based on advanced drilling tests[J]. Rock and Soil Mechanics, 2020, 41(7): 2494-2503. (in Chinese)
[13] WANG M N, ZHAO S G, TONG J J, et al. Intelligent classification model of surrounding rock of tunnel using drilling and blasting method[J]. Underground Space, 2021, 6(5): 539-550. doi: 10.1016/j.undsp.2020.10.001
[14] 王志坚. 郑万高铁隧道智能化建造技术研究及展望[J]. 隧道建设(中英文), 2021, 41(11): 1877-1890. WANG Zhijian. Status and prospect of intelligent construction technology of tunnel of Zhengzhou-wanzhou high-speed railway[J]. Tunnel Construction, 2021, 41(11): 1877-1890. (in Chinese)
[15] LI S C, LIU B, XU X J, et al. An overview of ahead geological prospecting in tunneling[J]. Tunnelling and Underground Space Technology, 2017, 63: 69-94. doi: 10.1016/j.tust.2016.12.011
[16] CHEN T Q, GUESTRIN C. XGBoost: a scalable tree boosting system[C]//Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. San Francisco, 2016.
[17] 吴贤国, 陈彬, 刘琼, 等. 基于LSSVM和NSGA-Ⅱ混凝土耐久性多目标配合比优化[J]. 隧道建设(中英文), 2020, 40(12): 1691-1699. WU Xianguo, CHEN Bin, LIU Qiong, et al. Optimization of multi-objective mix ratio for concrete durability based on LSSVM and NSGA-Ⅱ[J]. Tunnel Construction, 2020, 40(12): 1691-1699. (in Chinese)
[18] LUNDBERG S, LEE S I. A unified approach to interpreting model predictions[EB/OL]. 2017: arXiv: 1705.07874. https://arxiv.org/abs/1705.07874
[19] 公路隧道设计规范: JTG 3370.1—2018[S]. 北京: 人民交通出版社, 2018. Specifications for Design of Highway Tunnels: JTG 3370.1—2018[S]. Beijing: China Communications Press, 2018. (in Chinese)
[20] 梁铭, 彭浩, 解威威, 等. 基于超前钻探及优化集成算法的隧道围岩双层质量评价[J]. 隧道建设(中英文), 2022, 42(8): 1443-1452. LIANG Ming, PENG Hao, XIE Weiwei, et al. Double-layer quality evaluation of surrounding rock of a tunnel based on advance drilling and optimized integration algorithm[J]. Tunnel Construction, 2022, 42(8): 1443-1452. (in Chinese)
[21] 陈振宇, 刘金波, 李晨, 等. 基于LSTM与XGBoost组合模型的超短期电力负荷预测[J]. 电网技术, 2020, 44(2): 614-620. CHEN Zhenyu, LIU Jinbo, LI Chen, et al. Ultra short-term power load forecasting based on combined LSTM-XGBoost model[J]. Power System Technology, 2020, 44(2): 614-620. (in Chinese)
-
期刊类型引用(3)
1. 李斌,周立国,刘世涛. 探矿工程在地质资源勘查研究中的作用. 世界有色金属. 2024(02): 182-184 .  百度学术
百度学术
2. 刘乃飞,周浩,宋战平,刘廉柏超,陶磊. 盾构隧道围岩特性实时获取技术研究进展. 长沙理工大学学报(自然科学版). 2024(05): 86-103+135 . 百度学术
3. 肖浩汉,曹瑞琅,王玉杰,赵宇飞,孙彦鹏. 随钻监测数据预处理方法研究. 水利学报. 2024(11): 1379-1390 . 百度学术
其他类型引用(1)
-
其他相关附件
计量
- 文章访问数: 253
- HTML全文浏览量: 39
- PDF下载量: 98
- 被引次数: 4





